Submitted by Blueforce on Mon, 09/24/2018 - 06:46 Pro Licensee
Hi,
I just tried to send a message to all server owners and users and the server went in some loop and crached, I have tried to restart it through our IPMI controller but the servers goes down almost instantly after a restart and the network "goes down". Please advice what to do!
The server is a production server with lots of customers and it's currently down!
Regards, Leffe
Status:
Active
Files:
{kind=link}
Comments
Submitted by andreychek on Mon, 09/24/2018 - 09:28 Comment #1
Howdy -- thanks for contacting us!
I'm not quite sure what might be causing that kind of issue, and we haven't heard of anything like that occurring before.
How much time do you have between when you reboot, and when it's no longer accessible?
What you'd probably need to do is review the logs to see what's going on. It sounds like you're unable to access it remotely, do you have the ability to log into the console?
After a reboot, I'd be curious what output the following commands product:
uptimefree -m
df -h
mailq | tail -1
dmesg | tail -30
ps auxwf
I'd also review the log files in /var/log/ to see if they're showing any issues that offer clues as to what you're seeing there.
Submitted by Blueforce on Mon, 09/24/2018 - 11:25 Pro Licensee Comment #2
Hi Eric,
I finally did get the server online from the IPMI's remote java console. But I had to try many times to restart or shutdown the server. The restart worked most of the times but directly after startup it hang and the network went down. And finally I managed to shut it down completely. Then after a while I started it up again and directly when IPMI remote console got online I stopped Postfix service, it took several minutes for postfix to stop the service... and when it was stopped all other services came up and got responsive.
At this point I could log in to Webmin/Virtualmin and look at postfix queue, it had about 200 messages in queue. I was trying to send the message to about 240 recipients with the "Email server owners" feature.
I deleted all messages in queue and started postfix again and everything was looking fine again... but I had to get the message out to about 40 recipients, so I put the message in my desktops Outlook mail client and sent it to my self and the other 40 recipients in BCC. And when I hit "send" the server did the same thing again... got overloaded, got unresponsive, network going down... And again I had to shut it down with IPMI control and do the same thing again to get it up and running.
I don't know what is going on but it feels like something in mail/postfix/or an account is going in some loop or something like that...
Here are some info on our server:
CentOS Linux 7.5.1804
Webmin ver 1.890
Usermin ver 1.741, Virtualmin 6.03 Pro
Authentic Theme 19.20-beta2
Linux 3.10.0-862.11.6.el7.x86_64 on x86_64
Intel(R) Xeon(R) CPU E3-1220 v5 @ 3.00GHz, 4 cores
Running processes 220
CPU load averages 0.19 (1 min) 0.14 (5 mins) 0.14 (15 mins)
Real memory 743.59 MB used / 14.98 GB total
Virtual memory 357.97 MB used / 7.63 GB total
Local disk space 26.16 GB used / 896.50 GB free / 922.66 GB total
All installed packages are up to date
And here are the output from the first five commands.
[root@server ~]# uptime
17:41:10 up 1:21, 1 user, load average: 0.06, 0.10, 0.20
[root@server ~]# free -m
total used free shared buff/cache available
Mem: 15710 681 14046 17 981 14709
Swap: 7999 367 7632
[root@server ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 50G 11G 40G 21% /
devtmpfs 7.7G 0 7.7G 0% /dev
tmpfs 7.7G 4.0K 7.7G 1% /dev/shm
tmpfs 7.7G 18M 7.7G 1% /run
tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup
/dev/mapper/centos-home 873G 16G 857G 2% /home
/dev/sda1 497M 280M 218M 57% /boot
tmpfs 1.6G 0 1.6G 0% /run/user/0
[root@server ~]# mailq | tail -1
Mail queue is empty
[root@server ~]# dmesg | tail -30
[ 9.126331] intel_rapl: Found RAPL domain core
[ 9.126342] intel_rapl: Found RAPL domain dram
[ 9.300911] XFS (sda1): Mounting V4 Filesystem
[ 9.466882] power_meter ACPI000D:00: Found ACPI power meter.
[ 9.598598] power_meter ACPI000D:00: Found ACPI power meter.
[ 9.598664] power_meter ACPI000D:00: Ignoring unsafe software power cap!
[ 11.695437] XFS (dm-2): Mounting V4 Filesystem
[ 11.961414] XFS (dm-2): Starting recovery (logdev: internal)
[ 12.237648] XFS (dm-2): Ending recovery (logdev: internal)
[ 15.225432] XFS (sda1): Ending clean mount
[ 15.459187] type=1305 audit(1537798801.863:3): audit_pid=684 old=0 auid=4294967295 ses=4294967295 res=1
[ 15.818424] nf_conntrack version 0.5.0 (65536 buckets, 262144 max)
[ 15.852602] ip6_tables: (C) 2000-2006 Netfilter Core Team
[ 16.038979] microcode: updated to revision 0xc6, date = 2018-04-17
[ 16.044218] FEATURE SPEC_CTRL Present
[ 16.044224] FEATURE IBPB_SUPPORT Present
[ 16.044360] Speculative Store Bypass: Mitigation: Speculative Store Bypass disabled via prctl and seccomp
[ 16.045762] Spectre V2 : Mitigation: IBRS (kernel)
[ 16.439535] IPv6: ADDRCONF(NETDEV_UP): eno1: link is not ready
[ 16.486497] IPv6: ADDRCONF(NETDEV_UP): eno1: link is not ready
[ 16.488472] IPv6: ADDRCONF(NETDEV_UP): eno2: link is not ready
[ 16.535624] IPv6: ADDRCONF(NETDEV_UP): eno2: link is not ready
[ 18.166242] igb 0000:02:00.0 eno1: igb: eno1 NIC Link is Up 100 Mbps Full Duplex, Flow Control: RX
[ 18.166515] IPv6: ADDRCONF(NETDEV_CHANGE): eno1: link becomes ready
[ 24.304110] hcpdriver: loading out-of-tree module taints kernel.
[ 24.304114] hcpdriver: module license 'Proprietary' taints kernel.
[ 24.304115] Disabling lock debugging due to kernel taint
[ 24.304303] hcpdriver: module verification failed: signature and/or required key missing - tainting kernel
[ 24.305223] hcp: INFO: hcp driver loaded: 4.6.0 112, NR_CPUS: 5120
[ 24.305244] hcp: INFO: hcp_watchdog: started.
Regards, Leffe
Submitted by Blueforce on Mon, 09/24/2018 - 11:32 Pro Licensee Comment #3
One more thing...
the webmin log is filled with thousands of these lines,
Use of uninitialized value $settings{"settings_sysinfo_real_time_statu"...} in string eq at /usr/libexec/webmin/authentic-theme/stats.cgi line 25.Use of uninitialized value $settings{"settings_sysinfo_real_time_statu"...} in string eq at /usr/libexec/webmin/authentic-theme/stats.cgi line 25.
Use of uninitialized value $settings{"settings_sysinfo_real_time_statu"...} in string eq at /usr/libexec/webmin/authentic-theme/stats.cgi line 25.
Use of uninitialized value $settings{"settings_sysinfo_real_time_statu"...} in string eq at /usr/libexec/webmin/authentic-theme/stats.cgi line 25.
Use of uninitialized value $settings{"settings_sysinfo_real_time_statu"...} in string eq at /usr/libexec/webmin/authentic-theme/stats.cgi line 25.
Submitted by andreychek on Mon, 09/24/2018 - 11:41 Comment #4
Hmm, I've seen servers become unresponsive when they get extremely high amounts of email in the mail queue... but that's normally around the tens of thousands mark.
But I don't know of something on the Virtualmin side of things that might cause an issue like that with just 200 messages.
Let's ask Jamie though, maybe he has a thought --
Jamie, do you have any thoughts on why 200 messages in their mail queue might have such a heavy impact on server performance?
Submitted by Blueforce on Mon, 09/24/2018 - 12:04 Pro Licensee Comment #5
I also did look in Webmin Actions Log and there I see my test post to only our own domain, both owner and users and that post is in the Actions log with info on to whom message was sent. And as the test looked ok I sent the message to almost all domains owner and users and that is not registered in the Webmin Actions Log.
Postfix has "Max number of recipients per message delivery" set to 50, could that be the problem... I did count the recipients in my next try to send the message from my desktop mail client and there was 63 recipients that time. If this or some other Postfix limit is kicking in it has to do it in a more friendly way... ;-)
//Leffe
Submitted by andreychek on Mon, 09/24/2018 - 12:23 Comment #6
It sounds like you're referring to the "default_destination_recipient_limit". The default of that is 50, and that's a normal limit for that... I suspect that's not related to what you're seeing, but let's see what Jamie has to say about all that (Jamie, see my question in Comment #4 above).
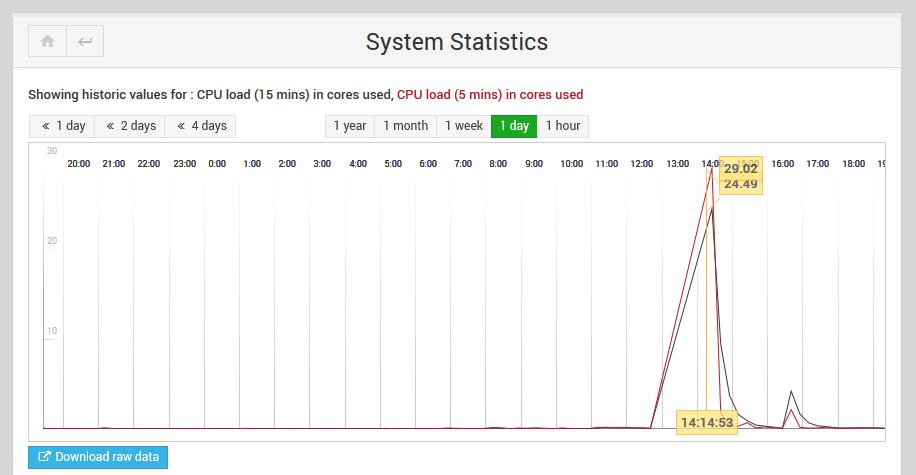
Submitted by Blueforce on Mon, 09/24/2018 - 12:45 Pro Licensee Comment #7
I uploaded a screenshot of System statistics - processor load 5 and 15 mins. when hitting send in "Email Server Owners"
//Leffe
Submitted by andreychek on Mon, 09/24/2018 - 12:56 Comment #8
Understood. Let's see what Jamie has to say :-)
He may not be able to respond until a little later, but he should have some input for us.
Jamie, see my question in Comment #4 above.
Submitted by JamieCameron on Mon, 09/24/2018 - 23:16 Comment #9
Were the 200 recipients of these messages on your system, or on remote mail servers?
I suppose that if you are doing virus checking if incoming email, a sudden influx of 200 messages could generate a lot of load.
Submitted by Blueforce on Tue, 09/25/2018 - 05:21 Pro Licensee Comment #10
Hi Jamie,
They all are on our system, on the same server. The same happened when I tried to send this message to 63 users from my mail client after I got the server up and running again, but that time I was able to get the server responding little bit faster through IPMI so that I could restart the server, and with IPMI remote console stop postfix and empty the mail queue. So in the end, almost no one has gotten my message since I had to remove them from the mail queue to get the server up and running.
The message was just a short information about a fraud/scam mail that is hitting Sweden hard at the moment, we had several worried customers contacting us. The message was plain text and rather short.
Many years ago we had a customer that got his computer hacked and the hacker did send spam from his mail account after he found his account password in his documents. We did notice this rather fast since the server got really slow due to the tens of thousands mails (and growing) in the postfix queue, and still that old server was up and running and did not just roll over and die...
Yes, the clamAV scanner is running but should that really kill almost all services, network and stuff by a simple message to 63 recipients!?!
I cant really see why this short message would bring a whole server down when sending it to 63 recipients as I tried last.
Regards, Leffe
Submitted by andreychek on Tue, 09/25/2018 - 11:21 Comment #11
Yeah, that's why I asked Jamie for some input -- my personal VPS, which is seemingly much lower-end than your server, doesn't run into issues like that when sending/receiving that volume of emails.
That is, I can't reproduce that issue on my own personal VPS.
That gives me an idea though -- if you go into Email Messages -> Spam and Virus Scanning, what is "SpamAssassin Client" and "Virus Scanning Program" set to?
Submitted by Blueforce on Tue, 09/25/2018 - 17:27 Pro Licensee Comment #12
Hi,
SpamAssasin is set to run standalone to be able to have different configs for our customers. ClamAV aso is running as standalone, how ever, the virus scanning I would prefer have running as server scanner with clamd, but the service can not be started, not from this menu or from system/bootup and Shutdown! I remeber now that it has been like this from the beginning when this new server was set up, at that moment I let it run as standalone for the time being, end then I forgot about it! I don't know what is wrong with it but clamd wont start.
//Leffe
Submitted by Blueforce on Tue, 09/25/2018 - 17:46 Pro Licensee Comment #13
I get this message when trying to start it from "Virtualmin/Email settings/Spam and Virus scanning"
Configuring and enabling the ClamAV scanning server ..
Starting ClamAV server and enabling at boot ..
.. done
.. all done
and this I get when trying to start from "Webmin/System/Bootup and Shutdown"
Starting service clamav-daemon.service ..
.. done.
but clamd don't start even if it says that.
//Leffe
Submitted by andreychek on Tue, 09/25/2018 - 18:07 Comment #14
Do you see any messages in /var/log/maillog when attempting to start ClamAV?
Also, what messages do you see if you attempt to start/restart the ClamAV service on the command line?
Submitted by Blueforce on Tue, 09/25/2018 - 18:15 Pro Licensee Comment #15
no messages in maillog
Redirecting to /bin/systemctl start clamd.serviceFailed to start clamd.service: Unit not found.
Submitted by Blueforce on Wed, 09/26/2018 - 08:41 Pro Licensee Comment #16
Hi,
Any ideas on why clamd wont start?
//Leffe
Submitted by andreychek on Wed, 09/26/2018 - 09:45 Comment #17
Hmm, just to verify which ClamAV packages are installed, what is the output of this command:
rpm -qa | grep -i clamSubmitted by Blueforce on Wed, 09/26/2018 - 13:05 Pro Licensee Comment #18
Hi,
this is the output.
[root@server ~]# rpm -qa | grep -i clam
clamav-scanner-0.99.2-3.el7.centos.vm.noarch
clamav-lib-0.99.2-3.el7.centos.vm.x86_64
clamav-data-0.99.2-3.el7.centos.vm.noarch
clamav-0.99.2-3.el7.centos.vm.x86_64
clamav-server-0.99.2-3.el7.centos.vm.x86_64
clamav-filesystem-0.99.2-3.el7.centos.vm.noarch
clamav-scanner-systemd-0.99.2-3.el7.centos.vm.noarch
clamav-update-0.99.2-3.el7.centos.vm.x86_64
clamav-server-systemd-0.99.2-3.el7.centos.vm.noarch
[root@server ~]#
Submitted by andreychek on Wed, 09/26/2018 - 13:09 Comment #19
Okay, try this command and let us know what output you see:
service clamd@scan.service restartSubmitted by Blueforce on Wed, 09/26/2018 - 17:49 Pro Licensee Comment #20
Hi,
Yes, thank you, it started with that command. I did try start the same service that the "Enable ClamAV Server" button in "Spam and Virus Scanning" also is trying to start and also set it to start at boot. The button is in other words trying to start the wrong service and also set wrong service to start at boot!
I can start it from command line and also in "Bootup and Shutdown".
Which of these services should be running and which should be set to start at boot if I use ClamAV server scanner.
clamav-daemon.serviceclamav-daemon.socket
clamav-freshclam.service
clamd@scan.service
Submitted by andreychek on Wed, 09/26/2018 - 22:01 Comment #21
I would start by having "clamd@scan.service" and "clamav-freshclam.service" start at boot, and if you run into trouble we can look into starting others.
But yeah, try using the server based ClamAV scanner, as that will use less CPU.
The same goes for SpamAssassin -- it will use more CPU when not using the server based scanner, but you're right that using the server-based scanner limits your options.
Submitted by Blueforce on Wed, 09/26/2018 - 22:43 Pro Licensee Comment #22
Isn't freshclam run from cron? Should "clamav-freshclam.service" be running anyway?
Is it only on our server the "Enable ClamAV Server" button in "Virtualmin/Email settings/Spam and Virus scanning" not working? It has been like this from when the server was new and installed with OS and Virtualmin Pro.
Submitted by andreychek on Wed, 09/26/2018 - 23:55 Comment #23
Freshclam runs as a service.
We haven't received similar reports for other servers, though we'll keep an eye out for that.
Has that helped your email issues though?
What I might try first is to just setup the ClamAV server scanner, and then do some testing.
I might try sending out smaller batches of emails and work your way up, to see if that improves performance.
When doing the testing, I'd keep a close eye on the system load, available RAM, and running processes. One way to do that would be to run the "top" command.
Submitted by Blueforce on Thu, 09/27/2018 - 19:06 Pro Licensee Comment #24
I have not have time to test yet, but I will do it as soon as i can.
Here are a few, and they all have same issue with not able to start ClamAV server in a "normal" way, so it look like the bug still exists:
https://www.virtualmin.com/node/41327
https://www.virtualmin.com/node/41189
https://www.virtualmin.com/node/40849
Regards, Leffe
Submitted by andreychek on Thu, 09/27/2018 - 19:40 Comment #25
Well, I meant recent reports :-) Those are from back in 2016, and in theory that was fixed back then.
However, we can go over that once we resolve the main issue that you're seeing here. Let us know how your testing goes!